
Over the past few months, I have been working on and off on this side-project called Quackcheck. This project was built to help me deal with the opacity of articles on the web. You see, I figured out that because of the unique way in which search-engines operate, relevance is often prioritised over accuracy.
What this means is that when doing research via Google Search, I often encounter articles that seem to answer the questions that I actually ask, but in truth make all sorts of assertions that they cannot back up. And these articles are often right at the top of Google’s organic search results.
But why does this happen?
The seemingly obvious answer to this is that in the field of Search Engine Optimisation, there are sometimes numerous ways in which search engine results can be gamed.
One prominent example was the use of link farms, which relied on the understanding that backlinks were essential to search engine rankings. The basic con went like this: because a backlink is so essential to search engine rankings, let’s
- Step 1: Create a network of websites
- Step 2: Link each of these sites to each other in an interconnected explosion of links
- Step 3: Let the above mesh of backlinks boost each site’s rankings
- Step 4: Dominate search results without any clear superiority in content
- Step 5: …
- Step 6: Profit???
Great for the website creators. Bad for user experience, usefulness and accuracy. Fortunately, Google eventually found a way to technologically neutralise this hack. Unfortunately, new strategies to game search results continue to evolve.
But in truth, I personally find that the above does not fully explain why accuracy is such a hard nut to crack. The reason, I believe, is something more fundamental.
Relevance, relevance, relevance
When it comes to the search for information, relevance is often in conflict with accuracy. Just because something is perfectly accurate, doesn’t mean it is relevant, and therefore useful.
Perhaps it helps to define both relevance and accuracy. Relevance in this context refers to how closely a search result’s content matches what a user is trying to find or find out. Accuracy however refers to how closely a search result’s content matches the truth. Both are important metrics, but can also come into conflict.
For example, what happens if a bit of content directly answers the possible health issues associated with coughing, but the answer always leads to death That’s WebMD for you, a case in point of a site that is usually among the top in Google’s search results (last I checked), but not necessarily great for accuracy.
In truth, relevance is actually in competition with accuracy, and search engine providers have to trade one off against the other in order to attain the most profitable useful user interactions.
And sometimes – or perhaps many a time – relevance wins.
Great, but is this a problem that we can even solve?
Now, i know that accuracy (or truth) is kinda fuzzy and subjective. In fact, there is a whole discipline about it, a.k.a. Philosophy and Epistemology (Theory of Knowledge), that has tried for millennia to untangle truth with the small t, from Truth with the big T. And even those two kinds are not the only variants.
Pretty daunting, if you ask me.
What we can do, however, is something a little more straightforward. We can borrow the concept of references from the well-established field of academia – and at least try to figure out if an article has done its proper homework in citing good and diverse sources.
The basic idea in academia is this: knowledge builds on knowledge, and good sources of knowledge have good foundations in other bits of knowledge. Articles with good references tell their readers that the author or authors have done the proper research.
My thinking is that we can borrow this concept and apply it to the rest of the written online literature. If an article I am reading is able to cite sources from
- A diverse range of sources, and/or
- A set of sources that I personally consider reputable
Then perhaps I might be able to trust that the authors have done their research, and are communicating thoughtful, insightful and (hopefully) accurate ideas.
Not a foolproof solution, but certainly better than nothing. And this is how Quackcheck works.
So what does Quackcheck do?
What Quackcheck does is it basically identifies all the outgoing links in the article you are reading, and groups up all the domains that the links go to. This way you can have a quick summary of all the links that the article references, including the number of times a domain is linked. Like so:
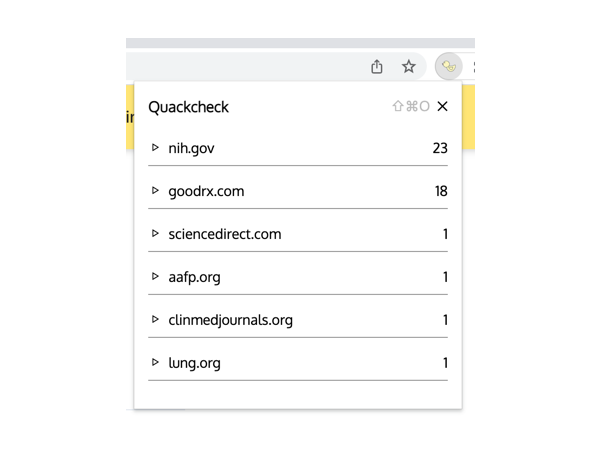
Interesting situations do occur from this insight. One of the most striking situations I personally encounter is one where all the links on a page are to pages on the same website. If it’s a government source, probably alright. If it’s a private for-profit ad-supported site, kinda sketchy, at least to me.
Taking it further: Mobile support via Telegram
One of the problems I faced with the browser extension only solution, was the lack of mobile support. Browser extensions work well on Desktop, but when it came to mobile, the experience fell short. Actually, the experience was non-existent.
That’s because most of the major browsers available do not support extensions on mobile. Also, I found it hard to conceive of how the extension would look in mobile format for the browser (Firefox) that did support it.
The solution, I figured, was a crude one: Why not just let users copy-paste a link into a Telegram chat, and get those same results? After all, Telegram is readily available on mobile. That’s how the Quackcheck Telegram bot was born.
Try it out
There are 3 different solutions available to curious quackcheckers, and I have the links to them below:
Here’s hoping Quackcheck helps warn at least one person away from unsubstantiated quacksites.